Με μια απλή αντικατάσταση του map container της STL (Standard Template Library) με το unordered_map του TR1 (C++ Technical Report 1), που ενσωματώθηκε πρόσφατα στη C++11, καθώς και κάποιες μικροδιορθώσεις στον κώδικα, με την απομάκρυνση κυρίως κάποιων "πλεονασμών", κατάφερα να διπλασιάσω σχεδόν την ταχύτητα του συλλαβιστή PomLex.
Ο συλλαβισμός 97.000 λέξεων (159.000 μεμονωμένων συλλαβισμών) σε σώμα κειμένου με 160.000 λέξεις επιτυγχάνεται μόλις σε 1,2 δευτερόλεπτα, ταχύτητα που θα ζήλευαν ακόμα και εμπορικά πακέτα συλλαβιστών γραμμένα από επαγγελματίες προγραμματιστές.
Για να έχετε μια τάξη μεγέθους, με έναν πρόχειρο υπολογισμό που έκανα, αυτό μεταφράζεται σε κείμενο 330 περίπου σελίδων μεγέθους Α4 με πλήρη στοίχιση (προεπιλεγμένα περιθώρια – 2,54 εκ. κατακόρυφα και 3,17 εκ. οριζόντια), μονό διάστημα γραμμής και γραμματοσειρά Andika 12 στιγμών.
Μετά απ’ αυτό νομίζω πως δεν χρειάζεται να το «σκαλίσω» άλλο το πράγμα, ούτε να «εκμηδενίσω» τους χρόνους είναι στις προθέσεις μου. Και πώς θα μπορούσε, εξάλλου, να γίνει κάτι τέτοιο; Ένας μελλοντικός στόχος όμως θα ήταν η ενσωμάτωση του συστήματος συλλαβισμού, μαζί με κάποιον «ορθογράφο» ίσως, σε κάποιον δημοφιλή, ανοιχτού κώδικα κατά προτίμηση, επεξεργαστή κειμένου, είτε ως πρόσθετο είτε απ’ ευθείας στο σώμα του πηγαίου κώδικα.
Οι αριθμοί που εμφανίζονται στις εικόνες είναι, βεβαίως, ενδεικτικοί, καθώς η ίδια η ταχύτητα του υπολογιστή παίζει καθοριστικό ρόλο. Οι μετρήσεις έγιναν σε διπύρηνο μηχάνημα με επεξεργαστή Intel Core 2 6400 στα 2.13 GHz με 2 GB RAM και λειτουργικό σύστημα Windows 7 (32-bit)
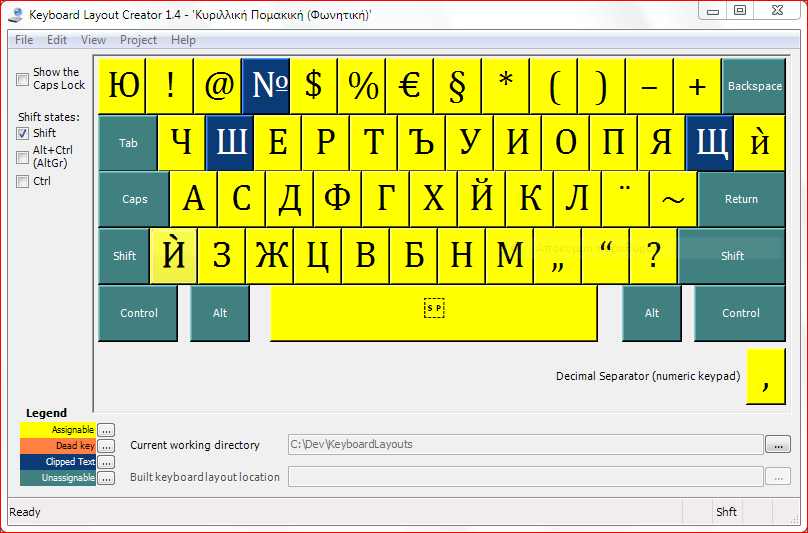
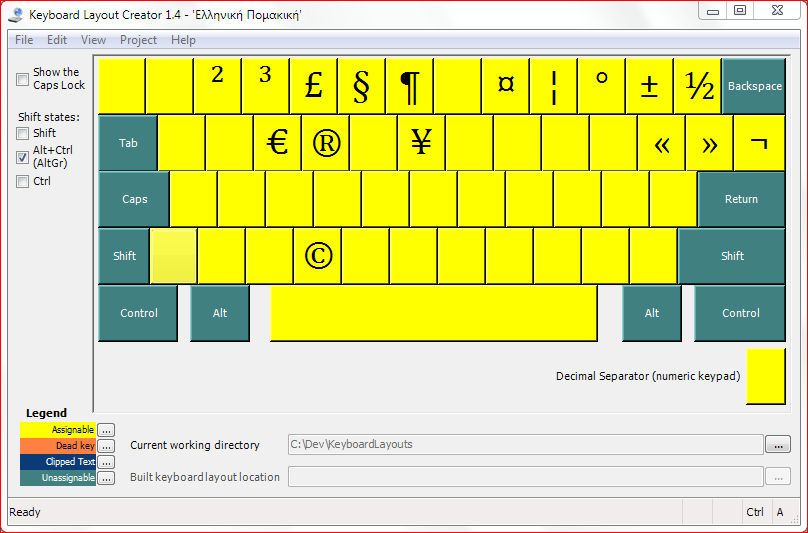
Ο συλλαβιστής θα μπορούσε να συλλαβίσει κείμενο σε οποιαδήποτε σχεδόν γλώσσα του κόσμου (με κάποια επιφύλαξη για τα σύνθετα συστήματα γραφής, όπως Κινέζικα, Αραβικά, Εβραϊκά κλπ.) με τους κατάλληλους κώδικες συλλαβισμού.




Κι εδώ ένα στιγμιότυπο με τον συλλαβιστή PomLex να τρέχει σε ένα τετραπύρηνο turbo laptop με επεξεργαστή Intel Core i7-3630QM στα 2.40 GHz με 16GB RAM σε λειτουργικό Windows 8 (64-bit). Η διαφορά στην ταχύτητα είναι σοκαριστική.

Ο συλλαβισμός 97.000 λέξεων (159.000 μεμονωμένων συλλαβισμών) σε σώμα κειμένου με 160.000 λέξεις επιτυγχάνεται μόλις σε 1,2 δευτερόλεπτα, ταχύτητα που θα ζήλευαν ακόμα και εμπορικά πακέτα συλλαβιστών γραμμένα από επαγγελματίες προγραμματιστές.
Για να έχετε μια τάξη μεγέθους, με έναν πρόχειρο υπολογισμό που έκανα, αυτό μεταφράζεται σε κείμενο 330 περίπου σελίδων μεγέθους Α4 με πλήρη στοίχιση (προεπιλεγμένα περιθώρια – 2,54 εκ. κατακόρυφα και 3,17 εκ. οριζόντια), μονό διάστημα γραμμής και γραμματοσειρά Andika 12 στιγμών.
Μετά απ’ αυτό νομίζω πως δεν χρειάζεται να το «σκαλίσω» άλλο το πράγμα, ούτε να «εκμηδενίσω» τους χρόνους είναι στις προθέσεις μου. Και πώς θα μπορούσε, εξάλλου, να γίνει κάτι τέτοιο; Ένας μελλοντικός στόχος όμως θα ήταν η ενσωμάτωση του συστήματος συλλαβισμού, μαζί με κάποιον «ορθογράφο» ίσως, σε κάποιον δημοφιλή, ανοιχτού κώδικα κατά προτίμηση, επεξεργαστή κειμένου, είτε ως πρόσθετο είτε απ’ ευθείας στο σώμα του πηγαίου κώδικα.
Οι αριθμοί που εμφανίζονται στις εικόνες είναι, βεβαίως, ενδεικτικοί, καθώς η ίδια η ταχύτητα του υπολογιστή παίζει καθοριστικό ρόλο. Οι μετρήσεις έγιναν σε διπύρηνο μηχάνημα με επεξεργαστή Intel Core 2 6400 στα 2.13 GHz με 2 GB RAM και λειτουργικό σύστημα Windows 7 (32-bit)
Ο συλλαβιστής θα μπορούσε να συλλαβίσει κείμενο σε οποιαδήποτε σχεδόν γλώσσα του κόσμου (με κάποια επιφύλαξη για τα σύνθετα συστήματα γραφής, όπως Κινέζικα, Αραβικά, Εβραϊκά κλπ.) με τους κατάλληλους κώδικες συλλαβισμού.




Κι εδώ ένα στιγμιότυπο με τον συλλαβιστή PomLex να τρέχει σε ένα τετραπύρηνο turbo laptop με επεξεργαστή Intel Core i7-3630QM στα 2.40 GHz με 16GB RAM σε λειτουργικό Windows 8 (64-bit). Η διαφορά στην ταχύτητα είναι σοκαριστική.